


The reality check: AI automates very little – only 3% of tasks solved
New paper exposes AI agents: Only 3% of tasks solved – more than monkeys typing endlessly, but far below all our expectations.

A few days ago, Cornell University's arxic published a paper entitled "Remote Labor Index: Measuring AI Automation of Remote Work" that puts the "agentic future" to the test: even the largest language models only successfully completed 3% of the tasks assigned to them. That sounds disappointing at first – but is it really? Or is it even more than you would expect from monkeys typing endlessly on computers?
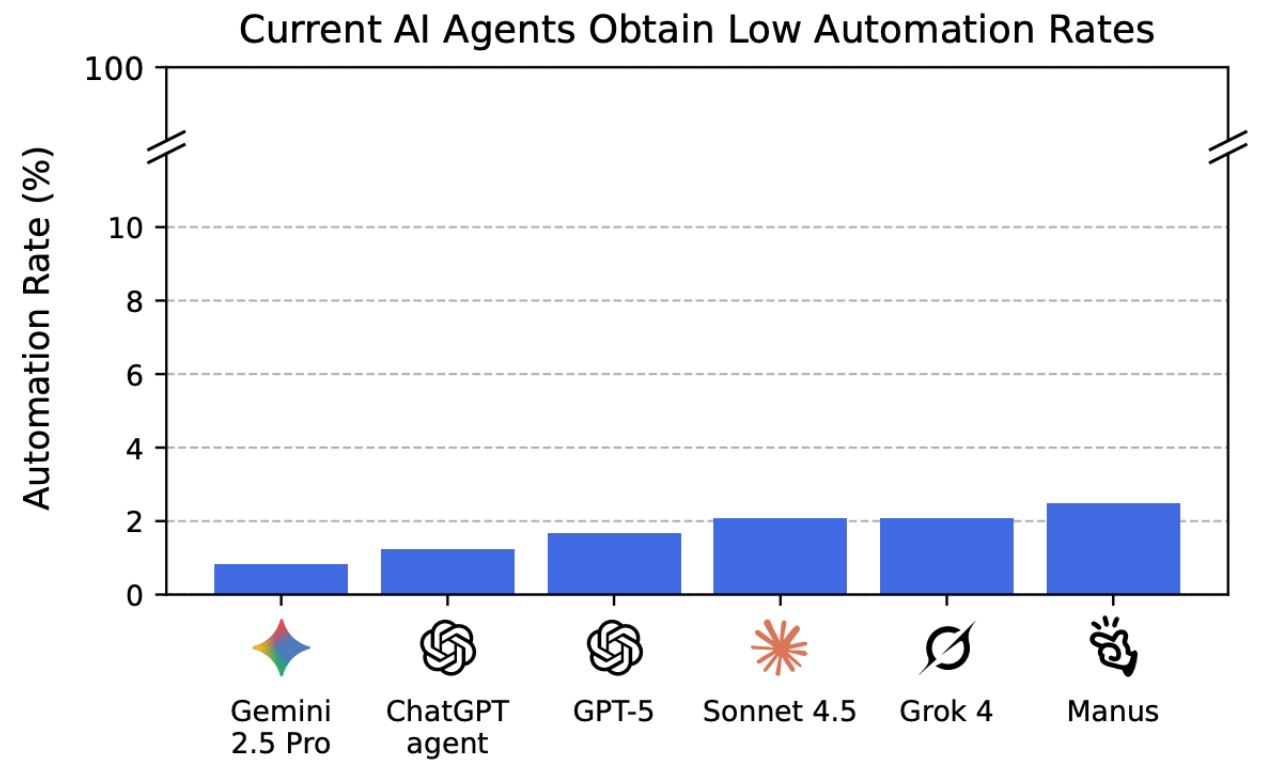
The advances in AI research benchmarks are impressive – but what do they achieve in the real world? This is precisely the question posed by the Remote Labor Index (RLI), a new, practical test that evaluates AI agents in real, economically relevant projects. The result is sobering; even the best systems achieve an automation rate of only 2.5%.
While AI excels in controlled tests, the RLI shows that it fails in complex, unpredictable real-world situations. The gap between the lab and practice is huge – and that raises questions: How much of the promised "AI revolution" is really more than just hype? The data provides a clear answer: We are still in the early stages. And anyone talking about AI-driven automation today should be aware that the empirical basis is thin – and that most "agents" cannot even reliably handle simple workflows. See also: Vibe coding: The AI agent illusion.

The illusion of autonomy
Apple spent months trying to turn Siri into a real "agent" – with limited success. The frustration was so great that internal papers were even written about the "non-intelligence" of LLMs (see: Apple study provides insights: Debunking AI superintelligence myths). But the problem does not necessarily lie in technology itself, but rather in our false expectations.
The core problem: accuracy vs. vagueness
Humans use language to create precision out of the fuzziness of the world. They organize chaos, fill in gaps, and create meaning. However, AI models work fundamentally differently. They are based on a fixed "latent space" – a space of possibilities for all answers created during training. From this artificial accuracy, they generate fuzziness again by deliberately adding "noise." The result often seems convincing, but conceptually it is something completely different from human thinking.
The more steps a task requires, the higher the critical error probability. This is not only due to the technology itself, but also to the fundamental nature of language models. Simple tasks pose little problem for them – here they can reliably follow a few logical steps. But with complex workflows, errors suddenly accumulate because each intermediate result introduces additional fuzziness into the process.
Michael Seemann calls this uncertainty "AI glow." It is this strange, almost tangible phenomenon that arises when language models appear to provide precise answers – but on closer inspection, everything seems to be covered by a soft, diffuse veil.
Language models behave like a mirror that becomes blurrier the more closely you try to look at it.
It is the blurriness that creeps into accuracy: the answers often sound convincing, but they are never quite sharp, never quite firm. Like light shining through frosted glass – you can see the contours, but the details are blurred.
But this AI glow effects not only the answers themselves, but also the behavior of the AI. The more you try to force clarity through precise prompts, the stronger the "answer noise" becomes – as if the system were becoming increasingly unpredictable under pressure.
AI does not give us sharpness, but an illusion of it.
Language models are like a distorted mirror: the closer you look, the more you demand them, the blurrier the image becomes. So, AI glow is not a coincidence, but a structural feature. AI does not give us sharpness, but an illusion of it.
The AI agent wall
Why Apple, and basically everyone else, is failing at the "AI agent wall" is obvious: reality reveals a structural limitation. AI agents are not thinkers, but pattern completers. They have no real "understanding" of goals but merely recognize patterns. But true autonomy requires much more: planning ability, memory, and a deep understanding of context – skills that language models do not (yet) master. For now, the "agentic future" remains a marketing term, not a technical reality.

Embrace the digital adoption platform of tomorrow - GRAVITY
The Digital Adoption Updates You Can't Miss - Subscribe Now!
Join Our Monthly Author Call – Stay Ahead of the Curve with the Latest Trends!
What does this mean for us?
We overestimate the capabilities of AI agents. They are not "digital assistants," but statistical text generators with limited logic.
The 3% success rate is not a failure, but a reality check. It shows how far we still are from true "agents."
The "glow" effect is everywhere. Whether in chatbots, automated workflows, or AI tools, the blurriness remains.
Conclusion: We are on the right track, but the AI agent wall is real
The "agentic future" is coming – but not in the way we imagine it. Perhaps we need completely new architectures that are not based purely on pattern recognition. Perhaps we need to accept that AI agents do not replace humans, but only function in narrowly defined niches.
One thing is certain: the 3% is a start. But it also shows that we still have a lot of work ahead of us – and that the biggest hurdle is not the technology, but our own understanding of what AI can do.

Christoph Müller
For years I used corporate Intranets in the workplace, experiencing firsthand that traditional learning formats for IT rollouts and employee onboarding do not work. I developed GRAVITY software to tackle this challenge. Employees are happier because learning is simple and effective; businesses are happier because their IT rollouts are successful and cost a lot less than before.



