


Der Realitätscheck: KI automatisiert kaum etwas – nur 3% der Aufgaben gelöst
Neues Paper entlarvt KI-Agenten: Nur 3 % der Aufgaben gelöst – mehr als endlos tippenden Affen, aber weit unter all unserer Erwartungen.

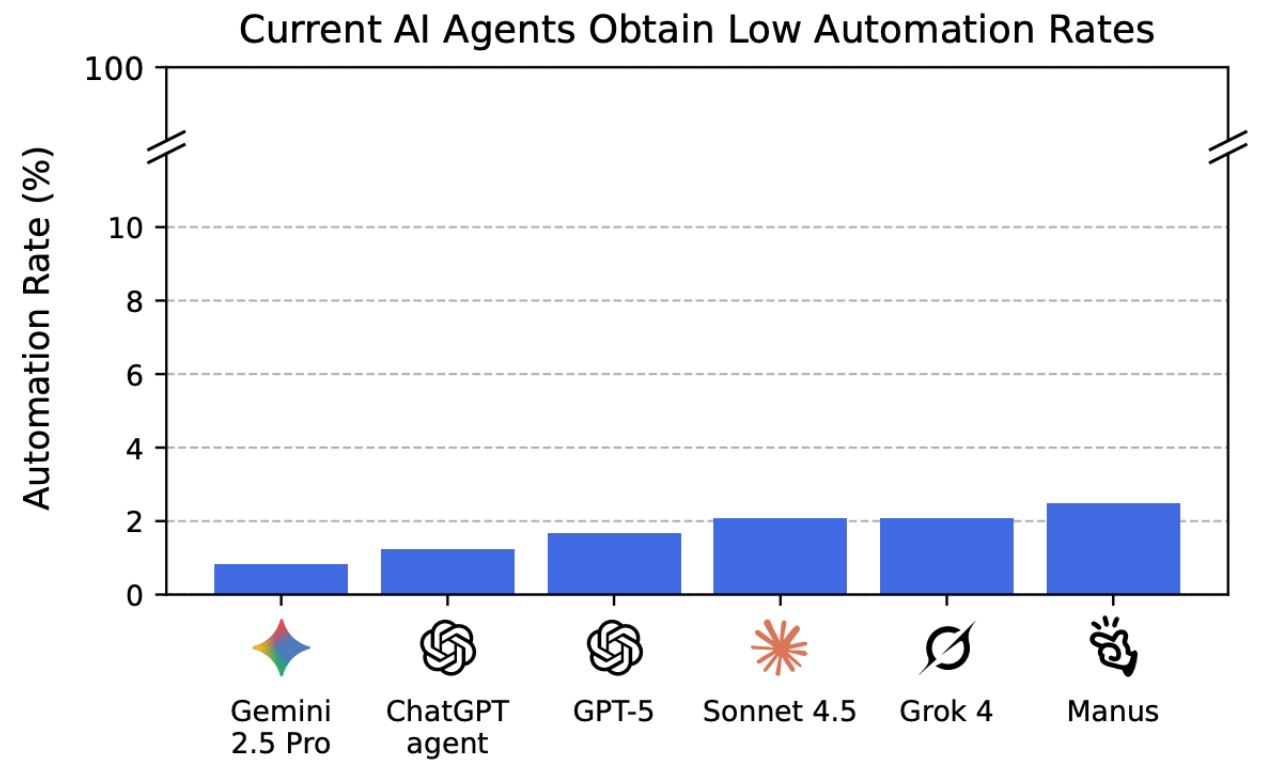
Vor ein paar Tagen erschien das Paper “Remote Labor Index: Measuring AI Automation of Remote Work” auf arxic der Cornell Universität, dass die „Agentic Future“ auf eine harte Probe stellt: Selbst die größten Sprachmodelle lösten nur 3 % der ihnen übertragenen Aufgaben erfolgreich. Das klingt erstmal enttäuschend – aber ist es das wirklich? Oder ist es sogar mehr, als man von endlos tippenden Affen an Computern erwarten würde?
Die Fortschritte der KI in Forschungs-Benchmarks sind beeindruckend – doch was bringen sie in der echten Welt? Genau diese Frage stellt der Remote Labor Index (RLI), ein neuer, praxisnaher Test, der KI-Agenten in realen, wirtschaftlich relevanten Projekten bewertet. Das Ergebnis ist ernüchternd: Selbst die besten Systeme erreichen eine Automatisierungsrate von nur 2,5 %.
Während KI in kontrollierten Tests glänzt, zeigt der RLI, dass sie in der komplexen, unberechenbaren Realität versagt. Die Lücke zwischen Labor und Praxis ist riesig – und das wirft Fragen auf: Wie viel der versprochenen „KI-Revolution“ ist wirklich mehr als nur Hype? Die Daten liefern eine klare Antwort: Wir stehen noch am Anfang. Und wer heute über KI-getriebene Automatisierung spricht, sollte sich bewusst sein, dass die empirische Basis dünn ist – und die meisten „Agenten“ noch nicht einmal einfache Arbeitsabläufe zuverlässig bewältigen. Siehe auch: Vibe-Coding: Die AI-Agenten-Illusion.

Die Illusion der Autonomie
Apple hat monatelang versucht, Siri zu einer echten „Agentin“ zu machen – mit mäßigem Erfolg. Die Frustration war so groß, dass intern sogar Papiere über die „Nicht-Intelligenz“ von LLMs verfasst wurden (siehe: Apples Studie gibt Einblicke: Entlarvung von KI-Superintelligenz-Mythen). Doch das Problem liegt nicht unbedingt in der Technologie selbst, sondern in unserer falschen Erwartungshaltung.
Das Kernproblem: Genauigkeit vs. Unschärfe
Menschen nutzen Sprache, um aus der Unschärfe der Welt Präzision zu schaffen. Sie ordnen Chaos, füllen Lücken und schaffen Bedeutung. KI-Modelle funktionieren jedoch grundlegend anders. Sie basieren auf einem fixen “Latent Space” – einem während des Trainings entstandenen Möglichkeitsraum aller Antworten. Aus dieser künstlichen Genauigkeit erzeugen sie durch gezieltes Hinzufügen von “Noise” wieder Unschärfe. Das Ergebnis wirkt oft überzeugend, ist aber konzeptionell etwas völlig anderes als menschliches Denken.
Je mehr Schritte eine Aufgabe erfordert, desto höher wird die kritische Fehlerwahrscheinlichkeit. Das liegt nicht nur an der Technologie selbst, sondern an der Grundnatur von Sprachmodellen. Einfache Aufgaben bereiten ihnen kaum Probleme – hier können sie einige logische Schritte zuverlässig verfolgen. Doch bei komplexen Workflows häufen sich plötzlich die Fehler, weil jedes Zwischenergebnis zusätzliche Unschärfe in den Prozess einbringt.
Diese Unschärfe nennt Michael Seemann der “KI-Glow”. Es ist dieses seltsame, fast greifbare Phänomen, das entsteht, wenn Sprachmodelle scheinbar präzise Antworten liefern – doch bei genauerem Hinsehen wirkt alles wie von einem sanften, diffusen Schleier überzogen.
Sprachmodelle verhalten sich wie ein Spiegel, der umso unschärfer wird, je genauer man ihn zu betrachten versucht.
Es ist die Unschärfe, die sich in die Genauigkeit einschleicht: Die Antworten klingen oft überzeugend, aber sie sind nie ganz scharf, nie ganz fest. Wie ein Licht, das durch Milchglas fällt – man erkennt die Konturen, doch die Details verschwimmen.
Doch dieser KI-Glow betrifft nicht nur die Antworten selbst, sondern auch das Verhalten der KI. Je mehr man versucht, durch präzise Prompts Klarheit zu erzwingen, desto stärker wird der “Antwort-Noise” – als würde das System unter Druck immer unberechenbarer.
Die KI gibt uns nicht Schärfe, sondern eine Illusion von ihr.
Sprachmodelle sind wie ein verzerrter Spiegel: Je genauer man hinschaut, je mehr man von ihnen verlangt, desto unschärfer wird das Bild. Der KI-Glow ist also kein Zufall, sondern ein strukturelles Merkmal. Die KI gibt uns nicht Schärfe, sondern eine Illusion von ihr.
Die KI-Agenten-Wand
Warum Apple und im Grunde alle anderen an der „KI-Agenten-Wand scheitern, liegt auf der Hand: Die Realität zeigt eine strukturelle Grenze auf. KI-Agenten sind keine Denker, sondern Mustervervollständiger. Sie besitzen kein echtes „Verständnis“ von Zielen, sondern erkennen lediglich Muster. Doch echte Autonomie erfordert weit mehr: Planungsfähigkeit, Gedächtnis und ein tiefes Kontextverständnis - Fähigkeiten, die Sprachmodelle (noch) nicht beherrschen. Die „Agentic Future“ bleibt vorerst ein Marketingbegriff, keine technische Realität.

Nutzen Sie die Digitale Adoption Plattform von morgen - GRAVITY
Die Updates zur digitalen Adoption, die Sie nicht verpassen dürfen – jetzt abonnieren!
Nehmen Sie an unserem "Author Call" teil - bleiben Sie mit den neuesten Trends auf der Höhe der Zeit!
Was bedeutet das für uns?
Wir überschätzen die Fähigkeiten von KI-Agenten. Sie sind keine „digitalen Assistenten“, sondern statistische Textgeneratoren mit begrenzter Logik.
Die 3%-Erfolgsquote ist kein Versagen, sondern ein Realitätscheck. Es zeigt, wie weit wir noch von echten „Agenten“ entfernt sind.
Der „Glow“-Effekt ist überall. Ob in Chatbots, automatisierten Workflows oder KI-Tools – die Unschärfe bleibt.
Fazit: Wir sind auf dem richtigen Weg, aber die KI-Agenten-Wand ist real
Die „Agentic Future“ wird kommen – aber nicht so, wie wir sie uns vorstellen. Vielleicht brauchen wir völlig neue Architekturen, die nicht auf reiner Mustererkennung basieren. Vielleicht müssen wir akzeptieren, dass KI-Agenten keine Menschen ersetzen, sondern nur in eng definierten Nischen funktionieren.
Eines ist sicher: Die 3% sind ein Anfang. Aber sie zeigen auch, dass wir noch viel Arbeit vor uns haben – und dass die größte Hürde nicht die Technologie ist, sondern unser eigenes Verständnis davon, was KI eigentlich kann.

Christoph Müller
Jahrelang habe ich Intranets von Unternehmen am Arbeitsplatz genutzt und dabei aus erster Hand erfahren, dass herkömmliche Lernformate für IT-Einführungen und die Einarbeitung von Mitarbeitern nicht funktionieren. Um dieser Herausforderung zu begegnen, habe ich die GRAVITY Software entwickelt. Die Mitarbeiter sind zufriedener, weil das Lernen einfach und effektiv ist; die Unternehmen sind zufriedener, weil ihre IT-Einführungen erfolgreich sind und viel weniger kosten als früher.
Letzte Blog-Artikel
Alle Beiträge anzeigen


